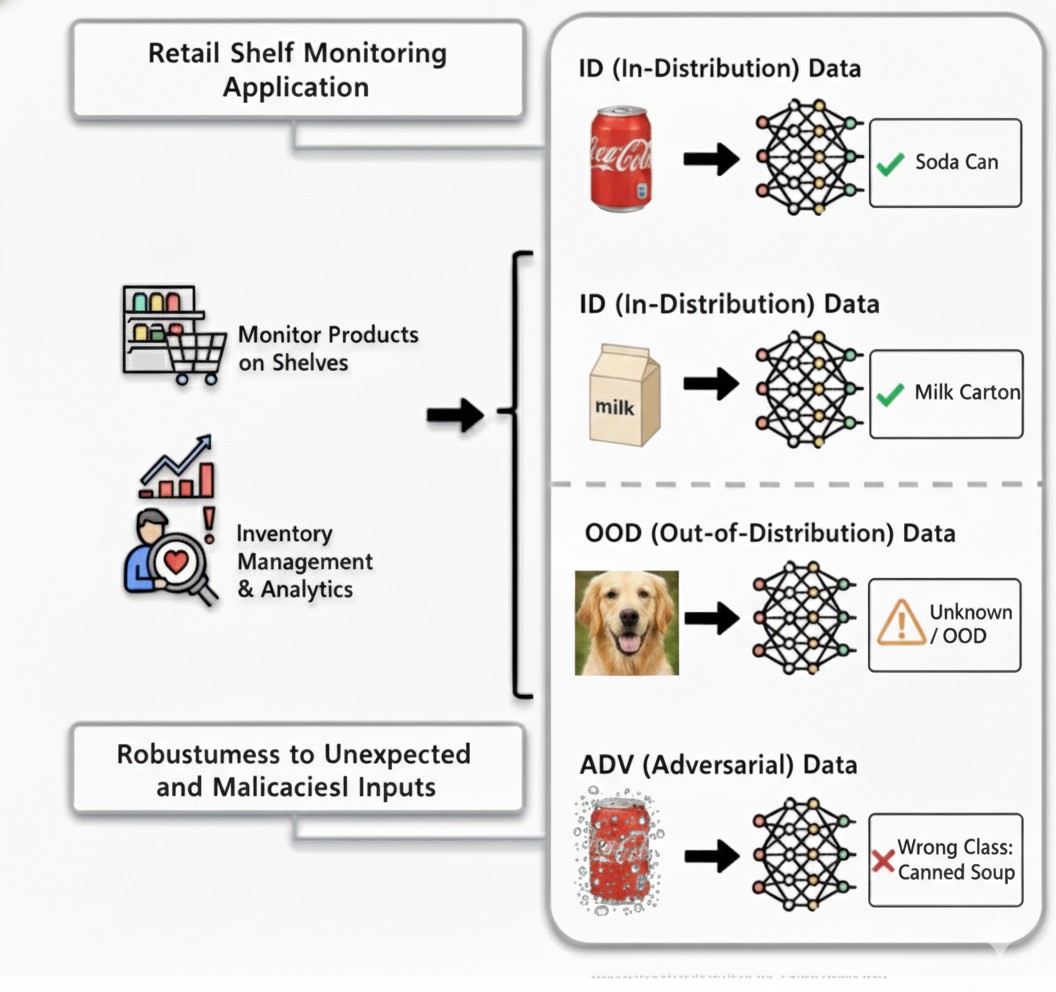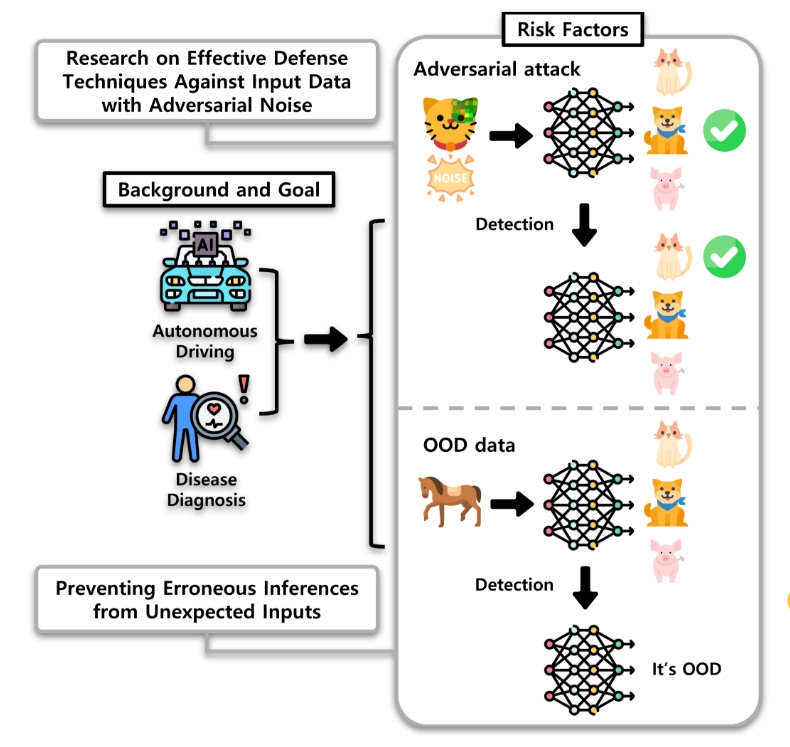
OOD vs ADV
Problem —
Out-of-distribution (OOD) inputs and adversarial (ADV) attacks both trigger detectors (e.g., Mahalanobis). But their root causes and mitigations are different — how do we reliably tell them apart so systems choose the right defense?
What I did —
- Designed a simple, post-hoc solution
- Separated OOD vs adversarial inputs after detection
- Enabled targeted, low-overhead mitigations